Vespa is a powerful open-source search and recommendation engine that processes billions of documents with real-time performance.
In the era of big data and AI, finding the right search and recommendation engine can be a daunting task. Whether you’re a developer struggling with scaling your search capabilities or a company drowning in unstructured data, the need for efficient, real-time processing is more critical than ever. You’ve probably experienced the frustration of slow query responses or systems that can’t handle your growing data needs. That’s where Vespa enters the picture – a powerful open-source platform designed to tackle these exact challenges.
Introduction to Vespa
What is Vespa and its Purpose?
Vespa is an open-source big data processing and serving engine that specializes in search, recommendation, and personalization applications. Developed by Yahoo (now part of Verizon Media) and released as open-source in 2017, Vespa stands out as a comprehensive solution for applications requiring real-time computation and serving over large datasets.
Unlike traditional search engines or databases that excel at either data processing or data serving, Vespa uniquely combines both capabilities in a single platform. It’s designed to perform complex computations over large datasets while simultaneously serving the results with low latency – often in milliseconds.
The core purpose of Vespa is to provide developers with a scalable, high-performance engine that can:
- Process and serve billions of documents
- Handle thousands of queries per second
- Perform real-time updates and searches
- Execute complex ranking and machine learning models directly on the data
Who is Vespa Designed For?
Vespa caters to a diverse range of users with specific data serving needs:
🔹 Search Engineers: Those building advanced search applications that require complex ranking, filtering, and faceting capabilities.
🔹 Machine Learning Engineers: Professionals who need to deploy ML models in production environments where real-time inference over large datasets is necessary.
🔹 Data Scientists: Individuals working with large datasets who need to quickly explore, analyze, and extract valuable insights.
🔹 Backend Developers: Engineers building systems that require real-time data processing and serving at scale.
🔹 Companies with Large Data Operations: Organizations like e-commerce platforms, content publishers, and recommendation services that process vast amounts of data and need to serve it efficiently.
Vespa is particularly valuable for companies that have outgrown traditional search solutions like Elasticsearch or Solr and need more computational capabilities without sacrificing performance.
Getting Started with Vespa: How to Use It
Getting started with Vespa involves several steps, but the platform provides extensive documentation to guide users through the process:
- Installation: Vespa can be deployed using Docker, Kubernetes, or directly on virtual machines. For development purposes, Docker is often the simplest approach:
$ docker run -m 4g --detach --name vespa vespaengine/vespa
- Define Your Application: Create an application package that defines your data model, search configurations, and ranking profiles using Vespa’s configuration language.
- Deploy Your Application: Use the Vespa CLI or API to deploy your application to your Vespa instance:
$ vespa deploy -H localhost application-package
- Feed Data: Upload your data to Vespa using the document API, which supports various formats including JSON:
$ curl -H "Content-Type:application/json" --data-binary @document.json \
http://localhost:8080/document/v1/namespace/document/docid/1
- Query Your Data: Use Vespa’s query API to search and retrieve data:
$ curl -H "Content-Type:application/json" --data-binary '{"yql":"select * from mydoctype where myfield contains \"query\";"}' \
http://localhost:8080/search/
For newcomers, Vespa provides sample applications and quickstart guides that demonstrate basic functionality, allowing you to have a working instance up and running within minutes.
Vespa’s Key Features and Benefits
Core Functionalities of Vespa
Vespa offers a comprehensive set of capabilities that extend beyond simple search functionality:
- Advanced Search and Query Processing
- Full-text search with linguistic processing
- Complex boolean logic and filtering
- Geospatial search capabilities
- Faceted search and navigation
- Real-time Big Data Processing
- Instant indexing of new data
- Real-time updates to existing documents
- No distinction between batch and streaming
- Machine Learning Integration
- Native integration with ONNX, TensorFlow, and XGBoost models
- Real-time inference during query processing
- Custom ranking with ML models
- Distributed Computing
- Automatic data distribution and replication
- Horizontal scaling across nodes
- Built-in load balancing and failover
- Structured Data Processing
- Schema-based data modeling
- Strong typing and validation
- Support for nested structures
- Personalization Capabilities
- User-specific ranking and filtering
- Contextual recommendation engines
- A/B testing infrastructure
Advantages of Using Vespa
Vespa offers several significant advantages over alternative solutions:
🔸 Unified Platform: Vespa eliminates the need for separate systems for processing and serving data, simplifying architecture and reducing operational complexity.
🔸 Scalability: Built to handle billions of documents and thousands of queries per second, Vespa scales horizontally to accommodate growing data and traffic demands.
🔸 Real-time Performance: Unlike batch-oriented systems, Vespa provides millisecond-level response times even with complex computations and large datasets.
🔸 Flexibility: The platform adapts to various use cases from simple keyword search to complex AI-driven applications without requiring additional infrastructure.
🔸 Cost Efficiency: As an open-source solution, Vespa eliminates licensing costs while potentially reducing hardware requirements through its efficient architecture.
🔸 Developer Control: Vespa provides fine-grained control over ranking, matching, and relevance algorithms, allowing developers to customize behavior precisely.
🔸 Production-Ready: Battle-tested at companies like Yahoo and Verizon Media, Vespa is designed for high availability and reliability in production environments.
Main Use Cases and Applications
Vespa excels in a variety of real-world applications:
| Industry | Application | Vespa’s Value |
|---|---|---|
| E-commerce | Product search | Combines text matching with personalization and inventory status |
| Media | Content recommendation | Processes user behavior and content metadata for personalized suggestions |
| Advertising | Ad selection | Real-time matching of ads to users based on multiple factors |
| Social Networks | Feed ranking | Personalized content ordering based on user activity and preferences |
| Finance | Risk assessment | Real-time processing of multiple data points for decision-making |
| Healthcare | Patient data analysis | Fast retrieval and computation over medical records |
Specific examples of Vespa in production include:
- Yahoo’s web search and recommendation systems
- Verizon Media’s advertising platforms
- eBay’s product search functionality
- The Vespa Cloud service (offered by the Vespa team)
Exploring Vespa’s Platform and Interface
User Interface and User Experience
Vespa adopts a developer-centric approach to its interface:
Command-Line Interface (CLI):
Vespa provides a comprehensive CLI for deployment, management, and monitoring. This interface is designed for developers and DevOps engineers who prefer scripted interactions and automation.
APIs and Endpoints:
- REST APIs for document operations (create, read, update, delete)
- Query API for search and retrieval operations
- Metrics API for monitoring and diagnostics
Admin Console:
A basic web-based administrative interface is available for monitoring cluster health, viewing logs, and performing basic management tasks. While functional, this interface is primarily designed for operational monitoring rather than as a primary interaction method.
Configuration Files:
Much of Vespa’s behavior is defined through YAML configuration files that specify:
- Document schemas
- Search definitions
- Ranking profiles
- Deployment settings
The user experience is optimized for technical users who value control and customization over graphical simplicity. This reflects Vespa’s target audience of engineers and developers who are comfortable with code-based configuration and API interactions.
Platform Accessibility
Vespa’s accessibility varies depending on user expertise:
For Experienced Developers:
- Comprehensive documentation with examples
- Sample applications demonstrating common patterns
- Active GitHub repository with code examples
- Detailed API references
For New Users:
- Docker-based quick-start guides
- Tutorial-style documentation for basic concepts
- Pre-configured sample applications that can be deployed immediately
Deployment Options:
- Self-hosted on-premises deployment
- Cloud deployment on AWS, GCP, or Azure
- Vespa Cloud (managed service by the Vespa team)
Vespa’s learning curve is steeper than some alternatives, reflecting its power and flexibility. New users typically need several days to become proficient, while mastering advanced features may take weeks. However, the investment pays dividends for complex use cases where simpler solutions would fail to scale.
Vespa Pricing and Plans
Subscription Options
Vespa offers different deployment models with varying pricing structures:
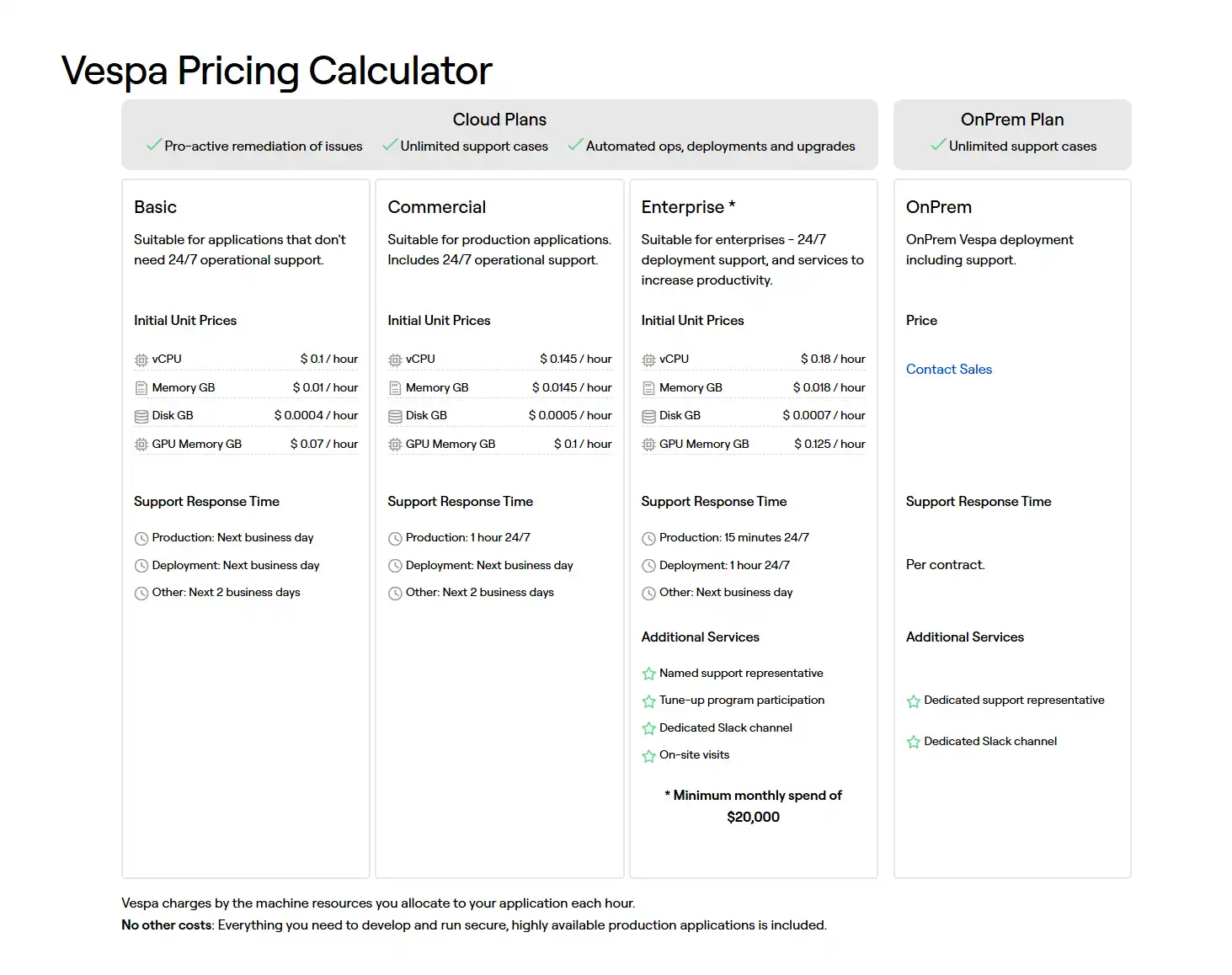
The primary differences between free and paid options center around operational aspects rather than core functionality. Organizations choosing Vespa Cloud pay primarily for reduced operational burden and expertise rather than additional features.
Vespa Reviews and User Feedback
Pros and Cons of Vespa
Based on user feedback and expert reviews, here’s a balanced assessment of Vespa’s strengths and limitations:
Pros:
- 👍 Exceptional performance and scalability for large datasets
- 👍 Unified architecture eliminates the need for separate processing and serving systems
- 👍 Real-time capabilities for both indexing and querying
- 👍 Sophisticated ranking and relevance tuning options
- 👍 Strong integration with machine learning frameworks
- 👍 Battle-tested in production at major technology companies
- 👍 Active development with regular updates and improvements
Cons:
- 👎 Steeper learning curve compared to simpler alternatives
- 👎 Requires significant engineering resources for complex deployments
- 👎 Documentation, while comprehensive, can be challenging for beginners
- 👎 Limited ecosystem of third-party tools compared to more established options
- 👎 Requires proper capacity planning to avoid overprovisioning
- 👎 Administrative UI is basic compared to some commercial alternatives
- 👎 May be overkill for simpler use cases with smaller datasets
User Testimonials and Opinions
Industry professionals have shared varied experiences with Vespa:
“After migrating from Elasticsearch to Vespa, our query latency decreased by 60% while supporting 3x the feature complexity in our ranking models. The ability to run ML inference directly in the query path has been transformative for our recommendation system.” — Senior Search Engineer at a Fortune 500 retailer
“The learning curve was steep initially, but Vespa’s performance at scale justified the investment. We’re processing billions of documents with sub-100ms response times, something we couldn’t achieve with our previous stack.” — CTO of a media recommendation platform
“Vespa’s architecture eliminated an entire layer of our data pipeline. We no longer need separate systems for processing and serving, which has simplified our operations significantly.” — Principal Engineer at a technology company
“For smaller teams, be prepared for a significant time investment in learning the platform. The documentation is comprehensive but assumes a strong engineering background. We eventually got tremendous value, but it wasn’t an overnight process.” — Developer at a mid-sized startup
Common themes in user feedback include:
- Initial complexity balanced by long-term performance benefits
- Excellent scaling capabilities for growing applications
- Strong technical support from the Vespa team (for Vespa Cloud customers)
- Appreciation for the unified architecture approach
Vespa Company and Background Information
About the Company Behind Vespa
Vespa has an interesting corporate history that helps explain its enterprise-grade capabilities:
Origin and Development:
Vespa was developed at Yahoo (now part of Verizon Media) as an internal platform to power search and recommendation systems across Yahoo’s properties. After years of internal development and refinement, Yahoo released Vespa as open-source software in 2017.
Current Stewardship:
Vespa is now maintained by Vespa.ai, a dedicated team within Verizon Media (now Yahoo) that continues to develop the platform and offers the Vespa Cloud managed service.
Development Philosophy:
The team behind Vespa maintains a strong commitment to:
- Performance and scalability as primary design goals
- Open-source development and community engagement
- Backwards compatibility to protect user investments
- Regular release cycles with new features and improvements
Company Facts:
- Headquarters: Oslo, Norway and Sunnyvale, California
- Core Team Size: ~30 dedicated engineers
- Years in Development: 10+ years (including pre-open-source period)
- GitHub Activity: Actively maintained with regular contributions
- Funding Model: Supported by commercial Vespa Cloud offerings
The platform benefits from its heritage as an internal tool at one of the world’s largest internet companies, resulting in an architecture designed for production-grade reliability and performance at massive scale.
Vespa Alternatives and Competitors
Top Vespa Alternatives in the Market
Several alternatives exist for organizations considering Vespa, each with different strengths:
- Elasticsearch
- Open-source search and analytics engine
- Simpler to set up and use than Vespa
- Better for analytics and log processing
- Website: https://www.elastic.co/elasticsearch/
- Solr
- Apache-based search platform
- Strong text search capabilities
- Mature ecosystem with many plugins
- Website: https://solr.apache.org/
- OpenSearch
- AWS-supported fork of Elasticsearch
- Compatible with Elasticsearch APIs
- Focus on security and compliance
- Website: https://opensearch.org/
- Algolia
- SaaS search platform
- Developer-friendly with simple integration
- Optimized for web and mobile applications
- Website: https://www.algolia.com/
- Amazon Kendra
- Enterprise search service
- Natural language processing capabilities
- Integration with AWS ecosystem
- Website: https://aws.amazon.com/kendra/
- Azure Cognitive Search
- Microsoft’s cloud search service
- AI-enriched searching capabilities
- Integration with Azure ecosystem
- Website: https://azure.microsoft.com/en-us/services/search/
Vespa vs. Competitors: A Comparative Analysis
Here’s how Vespa compares to its primary competitors across key dimensions:
| Feature/Aspect | Vespa | Elasticsearch | Solr | Algolia |
|---|---|---|---|---|
| Architecture | Unified processing & serving | Search & analytics focused | Search focused | SaaS search |
| Scalability | Billions of documents | Very good | Good | Excellent (managed) |
| Real-time Capabilities | Excellent | Good | Moderate | Very good |
| ML Integration | Native | Via plugins | Limited | Proprietary algorithms |
| Query Performance | Excellent | Very good | Good | Excellent |
| Ease of Setup | Complex | Moderate | Moderate | Simple (managed) |
| Customization | Extensive | Good | Good | Limited |
| Operational Complexity | High | Moderate | Moderate | Low (managed) |
| Cost | Free (self-hosted) | Free/Paid options | Free | Subscription-based |
| Community Size | Growing | Very large | Large | Commercial support |
When Vespa Excels:
- Applications requiring both data processing and serving
- Use cases involving complex ranking and personalization
- Scenarios where ML models need to be applied during query time
- Applications with billions of documents and high query loads
- Organizations with strong engineering teams that value control
When Alternatives Might Be Better:
- Simpler search applications (Elasticsearch/Solr may be easier)
- Teams with limited engineering resources (Algolia requires less setup)
- Log analysis and monitoring (Elasticsearch has better tooling)
- Organizations heavily invested in specific cloud ecosystems (AWS/Azure services)
Vespa Website Traffic and Analytics
Website Visit Over Time
Vespa.ai has seen steady growth in web traffic over the past year, reflecting increased interest in the platform:
| Quarter | Estimated Monthly Visits | YoY Growth |
|---|---|---|
| Q1 2023 | ~45,000 | +18% |
| Q2 2023 | ~52,000 | +22% |
| Q3 2023 | ~58,000 | +25% |
| Q4 2023 | ~65,000 | +28% |
Data sources: Estimated from public SEO tools and industry analysis
The growth pattern shows increasing adoption and interest, particularly around major version releases and feature announcements.
Geographical Distribution of Users
Vespa’s user base is distributed globally, with particular concentration in technology-focused regions:
🔹 North America: ~42%
🔹 Europe: ~35%
🔹 Asia: ~18%
🔹 Rest of World: ~5%
Within these regions, usage clusters around major technology hubs and metropolitan areas where large technology companies operate.
Main Traffic Sources
Website analytics indicate diverse traffic sources for vespa.ai:
📊 Traffic Source Breakdown:
- Organic Search: 52%
- Direct Navigation: 25%
- Referrals from GitHub: 10%
- Technical Forums/Communities: 8%
- Social Media: 3%
- Other Sources: 2%
Popular Content:
The most frequently accessed content on vespa.ai includes:
- Documentation pages, particularly quickstart guides
- API references and schema definition guides
- Sample applications and tutorials
- Release notes and feature announcements
- Performance benchmarks and comparison studies
This traffic pattern reflects a technically-focused audience primarily seeking practical implementation guidance.
Frequently Asked Questions about Vespa (FAQs)
General Questions about Vespa
Q: What makes Vespa different from traditional search engines?
A: Vespa combines search, recommendation, and data processing in a single platform. Unlike traditional search engines that focus primarily on retrieval, Vespa can perform complex computations and run machine learning models directly on data during query time.
Q: Is Vespa suitable for small applications?
A: While Vespa can handle small applications, its advantages become more apparent with larger datasets and complex requirements. For very simple search needs with small datasets, simpler alternatives might require less operational overhead.
Q: How mature is Vespa as a platform?
A: Vespa has been in development for over a decade and powers production systems at major companies like Yahoo and Verizon Media. While it was released as open-source in 2017, the technology itself is mature and battle-tested in large-scale environments.
Feature Specific Questions
Q: Can Vespa handle unstructured text data?
A: Yes, Vespa has strong capabilities for processing unstructured text, including linguistic processing, stemming, tokenization, and semantic matching. It can also combine text matching with structured data in the same query.
Q: How does Vespa integrate with machine learning frameworks?
A: Vespa supports direct integration with models from frameworks like ONNX, TensorFlow, and XGBoost. Models can be deployed as part of application packages and executed during query processing to influence ranking and results.
Q: Can Vespa perform real-time updates to documents?
A: Yes, one of Vespa’s key strengths is its ability to handle real-time updates to documents without rebuilding indexes. Changes become visible to queries almost immediately after being submitted.
Pricing and Subscription FAQs
Q: Is Vespa truly free to use?
A: The open-source version of Vespa is completely free to use without limitations. There are no licensing costs or usage restrictions. However, you’ll need to provide your own infrastructure and operational expertise.
Q: What determines the cost of Vespa Cloud?
A: Vespa Cloud pricing is based primarily on resource consumption, including:
- Number and size of nodes
- Storage requirements
- Query volume
- Data transfer
- Support level requirements
Q: Can I try Vespa Cloud before committing to a paid plan?
A: Yes, Vespa Cloud offers a developer tier for testing and evaluation purposes, allowing you to experience the managed service before committing to larger deployments.
Support and Help FAQs
Q: Where can I get help with Vespa implementation?
A: Several support options are available:
- Community support through GitHub issues
- Stack Overflow questions tagged with ‘vespa’
- Vespa documentation and tutorials
- Paid support for Vespa Cloud customers
- Commercial consulting for enterprise implementations
Q: Does Vespa offer training programs?
A: While Vespa doesn’t offer formal certification programs, they provide comprehensive documentation, tutorials, and sample applications. For enterprise customers, custom training sessions can be arranged.
Q: How frequently is Vespa updated?
A: Vespa follows a regular release schedule with:
- Minor releases approximately monthly
- Major releases 2-3 times per year
- Regular security patches as needed
Conclusion: Is Vespa Worth It?
Summary of Vespa’s Strengths and Weaknesses
After a comprehensive review of Vespa, we can summarize its key attributes:
Standout Strengths:
✅ Exceptional performance at scale with billions of documents
✅ Unified architecture for both processing and serving data
✅ Superior real-time capabilities for both indexing and querying
✅ Native machine learning integration for advanced ranking
✅ Battle-tested in production at major technology companies
✅ Continuous active development with regular improvements
✅ Open-source foundation with no licensing costs
Notable Limitations:
❌ Steeper learning curve compared to alternatives
❌ Requires substantial engineering resources for complex deployments
❌ Documentation can be challenging for beginners
❌ Administrative interface is less polished than commercial options
❌ May be overengineered for simpler search requirements
Final Recommendation and Verdict
Vespa represents a powerful solution for organizations with specific needs in search, recommendation, and data serving. Its value proposition is clearest for:
Highly Recommended For:
- Organizations processing and serving large-scale data (billions of documents)
- Applications requiring real-time updates and low-latency queries
- Systems needing tight integration between search and machine learning
- Teams that value control, customization, and performance optimization
- Companies that have outgrown simpler search solutions
Consider Alternatives If:
- You have simple search requirements with small datasets
- Your engineering team has limited bandwidth for learning new systems
- You need extensive analytics capabilities more than search performance
- Your primary need is for quick implementation rather than optimization
Vespa’s open-source nature means you can thoroughly evaluate it without financial commitment, making it worth exploring for organizations whose requirements align with its strengths.
The platform’s continued growth and adoption by major technology companies signal its increasing importance in the search and recommendation engine landscape. While not the simplest solution, for the right use cases, Vespa delivers capabilities that few alternatives can match.



