Chroma is an open-source embedding database that makes it easy to build LLM applications with powerful semantic search capabilities.
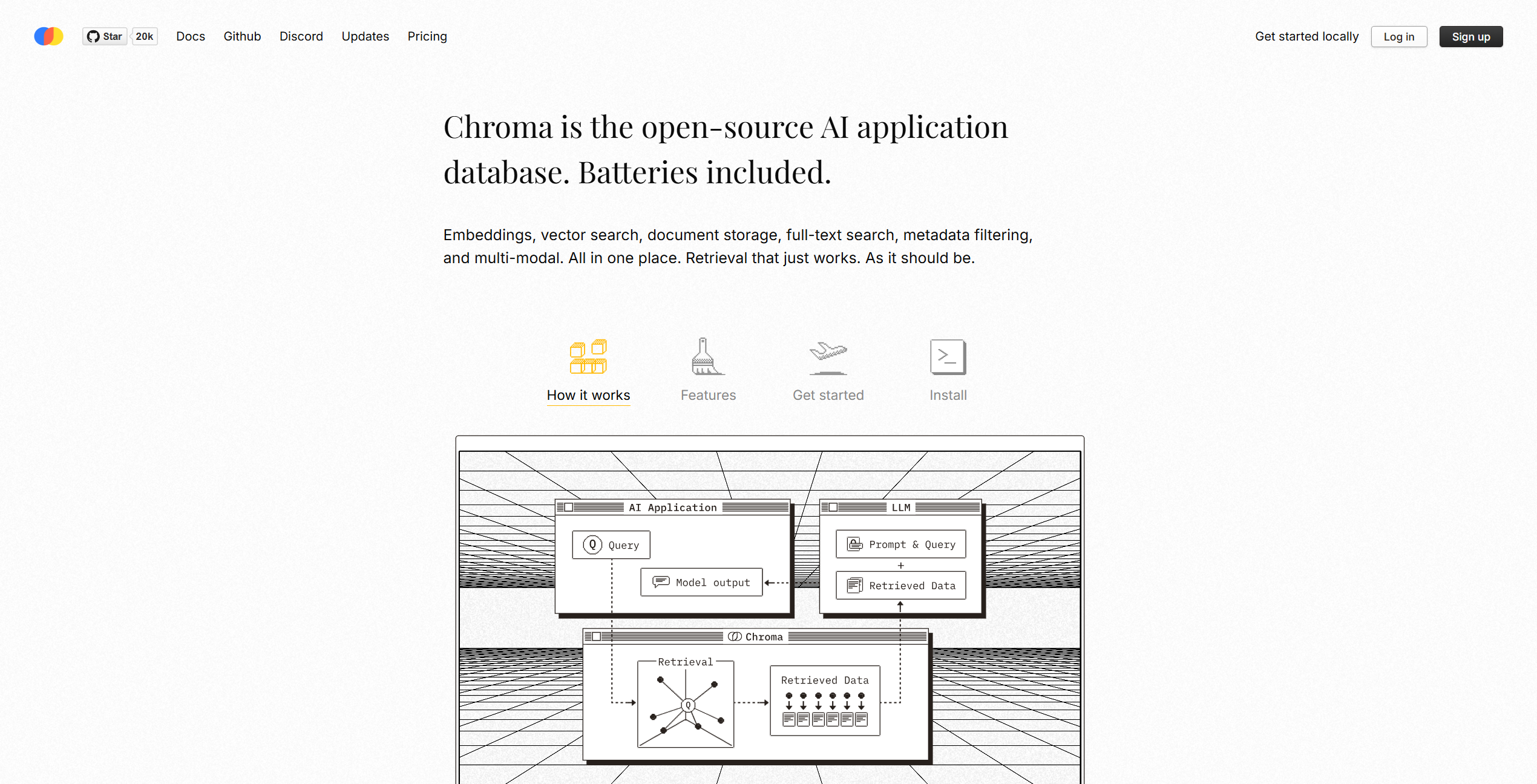
Introduction to Chroma
In today’s AI-driven development landscape, managing and retrieving vector embeddings efficiently has become crucial for building powerful semantic search applications. If you’ve been struggling with embedding management for your AI projects, you’re not alone. Many developers find themselves cobbling together custom solutions or wrestling with complex systems that weren’t designed for their specific needs. That’s where Chroma comes in – an open-source embedding database designed to simplify how we store, manage, and search vector embeddings.
What is Chroma and its Purpose?
Chroma is an open-source embedding database that makes it simple to build LLM applications by making knowledge, facts, and skills pluggable for LLMs. It’s designed to store and manage vector embeddings – those numerical representations of data (like text, images, or audio) that capture semantic meaning in a way machines can understand.
The core purpose of Chroma is to provide developers with a powerful yet accessible tool for creating semantic search functionality in their applications. It serves as the bridge between your raw data and the AI models that need to understand and work with that data in a meaningful way.
Chroma allows you to:
- Store and manage embeddings from various sources
- Query those embeddings for semantic similarity
- Build applications that can understand and retrieve information based on meaning rather than just keywords
Who is Chroma Designed For?
Chroma is primarily designed for:
- AI Engineers and ML Practitioners: Those building applications that leverage large language models (LLMs) and need efficient vector storage and retrieval
- Software Developers: Building search functionality that goes beyond traditional keyword matching
- Data Scientists: Looking to implement semantic similarity searches in their projects
- Researchers: Exploring vector embeddings and their applications
- Teams of Any Size: From individual developers to large organizations building enterprise-scale applications
Whether you’re creating a question-answering system, implementing semantic search for a document repository, or building a recommendation engine, Chroma provides the foundational infrastructure needed to make these applications possible.
Getting Started with Chroma: How to Use It
Getting started with Chroma is straightforward. Let’s walk through the basic steps:
- Installation:
pip install chromadb - Basic Usage:
import chromadb # Create a client client = chromadb.Client() # Create a collection collection = client.create_collection("my_collection") # Add documents to the collection collection.add( documents=["This is a document about cats", "This document is about dogs"], metadatas=[{"source": "cats.txt"}, {"source": "dogs.txt"}], ids=["doc1", "doc2"] ) # Query the collection results = collection.query( query_texts=["I love pets"], n_results=2 ) - Working with Embeddings: Chroma can either generate embeddings for you using its default models, or you can provide your own embeddings from custom models:
# Using custom embeddings collection.add( embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4]], documents=["Document 1", "Document 2"], ids=["id1", "id2"] )
Chroma offers both a local in-memory mode for development and a persistent mode for production. Its client-server architecture allows for flexible deployment options, from running everything on a single machine to distributed setups.
Chroma’s Key Features and Benefits
Core Functionalities of Chroma
Chroma comes packed with essential functionalities that make it a standout solution for embedding management:
- Flexible Embedding Storage:
- Store vector embeddings from any source
- Support for multiple embedding models and types
- Metadata association with your vectors
- Powerful Querying Capabilities:
- Similarity search using vector distance metrics
- Filtering based on metadata
- Hybrid search combining embedding similarity with metadata filters
- Collection Management:
- Organize embeddings into collections
- Add, update, and delete embeddings as needed
- Batch operations for efficiency
- Persistence Options:
- In-memory storage for development
- Persistent storage for production
- Client-server architecture for scalability
- Embedding Generation:
- Built-in support for popular embedding models
- Option to use custom embedding functions
- API Flexibility:
- Python client library
- REST API for language-agnostic access
- JavaScript/TypeScript client
Advantages of Using Chroma
🚀 Simplicity and Developer Experience
Chroma prioritizes developer experience with clean APIs and intuitive design. This means less time configuring and more time building.
⚡ Performance
Engineered for speed with efficient vector operations, even with large collections of embeddings.
🔌 Seamless Integration
Works well with popular ML frameworks and LLM platforms, making it easy to incorporate into existing workflows.
🔧 Customizability
Can be tailored to specific needs with custom distance metrics, embedding functions, and storage backends.
📈 Scalability
Designed to grow with your application from prototype to production.
💻 Open Source
Being open source means transparency, community contributions, and no vendor lock-in.
Main Use Cases and Applications
Chroma enables a wide range of applications across various domains:
🔍 Semantic Search Systems
Build search engines that understand the meaning behind queries, not just keywords.
# Example: Semantic search implementation
collection = client.create_collection("articles")
collection.add(
documents=[article1, article2, article3, ...],
ids=["id1", "id2", "id3", ...]
)
results = collection.query(
query_texts=["Recent advancements in renewable energy"],
n_results=5
)
❓ Question Answering
Power systems that can find precise answers to questions within large document collections.
🤖 Chatbots and Conversational AI
Give your chatbots the ability to retrieve relevant information from knowledge bases to inform their responses.
📊 Recommendation Systems
Suggest content, products, or services based on semantic similarity.
📄 Document Management
Organize and retrieve documents based on their content and meaning rather than rigid categorizations.
🔬 Research and Analysis
Analyze relationships between texts, identify patterns, and extract insights from large corpora.
Exploring Chroma’s Platform and Interface
User Interface and User Experience
Chroma primarily offers a code-based interface through its API rather than a graphical user interface. This prioritizes integration into development workflows and programmatic access.
The Python API is clean and intuitive, following familiar patterns that make it accessible even to those new to vector databases:
# The core API follows a logical pattern:
# 1. Create a client
# 2. Create/get a collection
# 3. Add data
# 4. Query data
client = chromadb.Client()
collection = client.create_collection("my_collection")
collection.add(documents=["document1", "document2"], ids=["id1", "id2"])
results = collection.query(query_texts=["my query"], n_results=2)
For those who prefer a more visual approach, there are community-built UI tools that wrap around Chroma’s API to provide graphical interfaces, though these aren’t part of the core offering.
The documentation is comprehensive and well-structured, with plenty of examples to help users get started quickly. This is particularly valuable given the technical nature of working with vector embeddings.
Platform Accessibility
Chroma is designed to be accessible across various platforms and deployment scenarios:
Installation Options:
- Python package (
pip install chromadb) - Docker containers
- From source (for those who want to customize or contribute)
Deployment Flexibility:
- Local development mode (in-memory)
- Persistent mode for production
- Client-server architecture for distributed setups
Language Support:
- Primary Python client
- JavaScript/TypeScript client
- HTTP REST API for other languages
Integration with Tools:
- Seamless integration with LangChain
- Works with popular embedding models (OpenAI, HuggingFace, etc.)
- Compatible with most ML frameworks
Chroma’s platform is designed to meet developers where they are, providing the flexibility to adapt to different workflows and requirements while maintaining a consistent core experience.
Chroma Pricing and Plans
Subscription Options
Chroma operates with a dual approach to its offering:

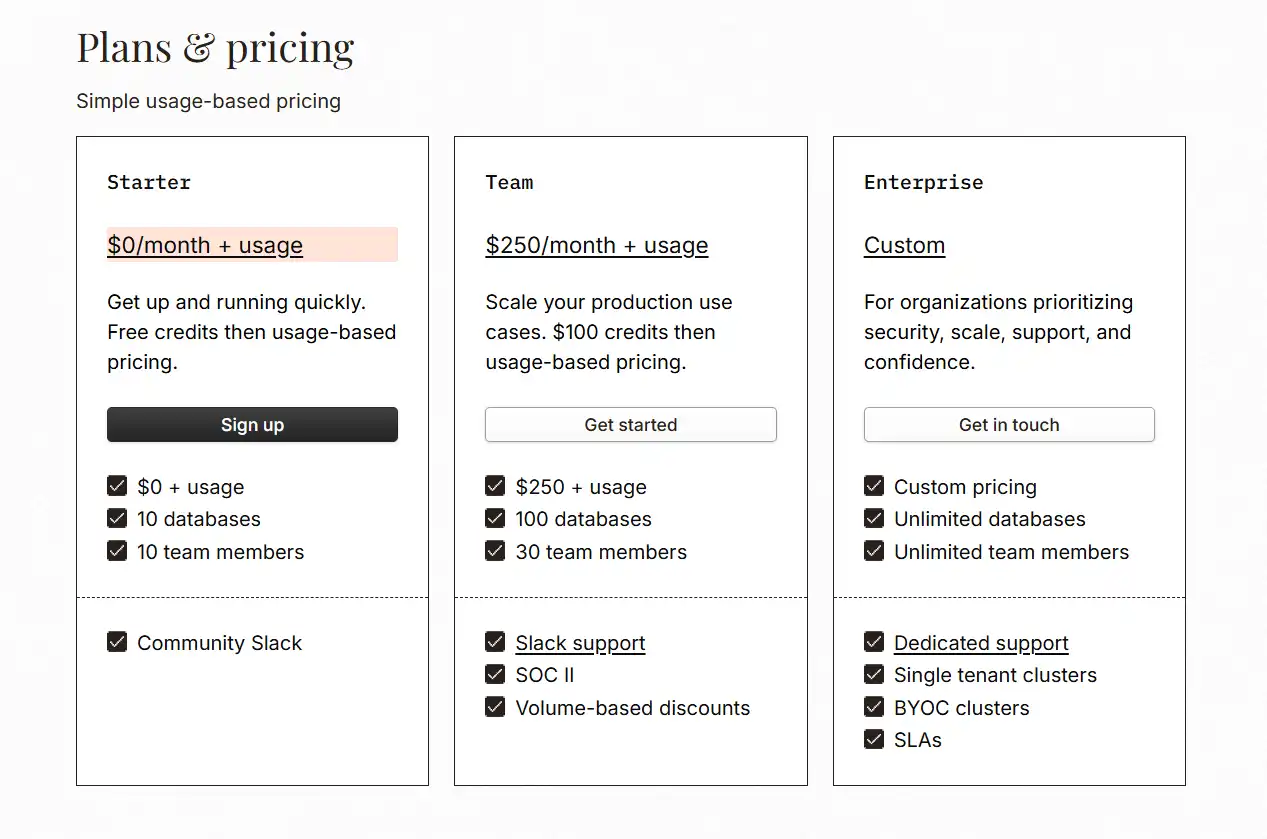
It’s worth noting that Chroma’s approach aligns with many modern open-source projects – providing a fully functional core that everyone can use while offering value-added services for enterprise customers.
Chroma Reviews and User Feedback
Pros and Cons of Chroma
Pros:
- 🚀 Ease of Use: Consistently praised for its simple, developer-friendly API
- 🔌 Integration Capabilities: Works seamlessly with popular tools like LangChain
- 🔧 Flexibility: Supports various embedding models and deployment options
- 🏎️ Performance: Good query performance even with larger datasets
- 💻 Open Source: Transparency and ability to customize
- 👥 Active Development: Regular updates and responsive to community feedback
Cons:
- 📈 Scaling Limitations: Some users report challenges when scaling to very large datasets in the open-source version
- 🛠️ Advanced Features: Some specialized features available in commercial vector databases are not yet implemented
- 📚 Documentation Gaps: While generally good, documentation for advanced use cases could be improved
- 🔄 Evolving API: Being a relatively new project, there have been some API changes that require updates
- 📱 Mobile Support: Limited options for mobile integration
User Testimonials and Opinions
From GitHub discussions and community forums:
“Chroma has simplified our RAG implementation significantly. What used to take weeks to set up now takes hours. The simplicity of the API is its biggest selling point.” – AI Engineer at a tech startup
“We evaluated several vector databases and chose Chroma for our semantic search feature. Its integration with our existing Python stack was seamless, and performance has been solid.” – Data Scientist
“The open-source nature of Chroma was crucial for our team. We needed to customize certain aspects of the vector search, and having access to the source code made this possible.” – ML Platform Engineer
“For smaller projects, Chroma is perfect. As we scaled to millions of embeddings, we did hit some performance bottlenecks, but the team was responsive in helping us optimize.” – ML Ops Specialist
Community sentiment generally skews positive, with Chroma earning praise for making vector databases accessible to a broader range of developers. The most common criticisms relate to scaling very large deployments and some missing advanced features found in more mature (but often more complex) alternatives.
Chroma Company and Background Information
About the Company Behind Chroma
Chroma was created by Trychroma, Inc., a company founded by Jeff Huber, Anton Troynikov, and James Kelley, who recognized the need for better tooling around embeddings as LLMs gained prominence.
Company Mission:
To make AI development more accessible by providing open-source infrastructure for working with embeddings and LLMs.
Founding and Growth:
- Founded in 2022
- Secured $14 million in seed funding led by Index Ventures in 2023
- Has grown rapidly alongside the explosion of interest in building with LLMs
Team Composition:
The Chroma team consists of experienced engineers and researchers with backgrounds in machine learning, distributed systems, and developer tools. Many team members come from leading AI research organizations and tech companies.
Open Source Philosophy:
Chroma maintains a strong commitment to open source, believing that fundamental AI infrastructure should be accessible to all developers. This philosophy guides their business model, which focuses on providing value-added services around the open core.
Community Engagement:
The Chroma team is active in the AI open-source community, regularly contributing to discussions, hosting office hours, and participating in events focused on LLM development and vector databases.
The company operates with a remote-first approach, with team members distributed across various locations, primarily in the United States.
Chroma Alternatives and Competitors
Top Chroma Alternatives in the Market
1. Pinecone
A managed vector database service with a focus on production-ready deployments and scalability.
- Key Differentiators: Fully managed service, advanced indexing methods, enterprise features
- Website: Pinecone
2. Weaviate
An open-source vector search engine with GraphQL integration.
- Key Differentiators: GraphQL interface, multimodal support, modular architecture
- Website: Weaviate
3. Milvus
An open-source vector database built for scalable similarity search.
- Key Differentiators: Highly scalable, supports multiple index types, active in AI research
- Website: Milvus
4. Qdrant
A vector similarity search engine with extensive filtering capabilities.
- Key Differentiators: Strong filtering options, written in Rust for performance
- Website: Qdrant
5. FAISS (Facebook AI Similarity Search)
A library for efficient similarity search developed by Facebook Research.
- Key Differentiators: Highly optimized for performance, numerous indexing methods
- Website: FAISS
Chroma vs. Competitors: A Comparative Analysis
| Feature | Chroma | Pinecone | Weaviate | Milvus | Qdrant |
|---|---|---|---|---|---|
| Ease of Use | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| Scalability | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Performance | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Deployment Options | Local, Self-hosted | Managed | Self-hosted, Cloud | Self-hosted, Cloud | Self-hosted, Cloud |
| Pricing Model | Open Source + Cloud | Paid, Usage-based | Open Source + Cloud | Open Source + Cloud | Open Source + Cloud |
| Language Support | Python, JS | Python, Node.js, Go | Python, Go, JS | Python, Java, Go | Python, Rust, JS |
| Integration with LLMs | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| Filtering Capabilities | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Community Activity | High | Medium | High | High | Medium |
When to Choose Chroma:
- You value simplicity and developer experience
- You’re building LLM applications that need vector search
- You want an open-source solution with a clean API
- You’re using LangChain or similar frameworks
When to Consider Alternatives:
- You need maximum scalability for billions of vectors (Milvus, Pinecone)
- You want a fully managed service with minimal setup (Pinecone)
- You need specialized indexing methods (FAISS)
- You’re working with multimodal data types (Weaviate)
- Advanced filtering is a top priority (Qdrant)
Chroma Website Traffic and Analytics
Website Visit Over Time
The trychroma.com website has seen significant growth in traffic over the past year, reflecting the increasing interest in vector databases and LLM application development.
While exact traffic numbers aren’t publicly disclosed, industry analytics tools suggest:
- Monthly Visits: Estimated 75,000-120,000 monthly visits
- Growth Trend: ~15-20% quarterly growth in website visits
- Page Views: Average 2.3 pages per visit
- Visit Duration: Average session duration of approximately 3:45 minutes
This growth pattern aligns with the broader expansion of the RAG (Retrieval-Augmented Generation) approach to building LLM applications, which has driven interest in vector databases.
Geographical Distribution of Users
Chroma’s user base is distributed globally, though with concentration in tech hubs:
🇺🇸 United States: ~40% of traffic
🇬🇧 United Kingdom: ~8% of traffic
🇩🇪 Germany: ~7% of traffic
🇮🇳 India: ~6% of traffic
🇨🇦 Canada: ~5% of traffic
🌏 Other Countries: ~34% of traffic
This distribution suggests Chroma has achieved good penetration in major tech markets while maintaining a global presence.
Main Traffic Sources
Chroma’s website traffic comes from diverse sources:
- Organic Search: ~35% (primarily from search terms related to vector databases, embedding storage, and LLM tools)
- Direct Traffic: ~25% (indicating strong brand recognition)
- GitHub Referrals: ~15% (showing strong integration with the developer ecosystem)
- Social Media: ~10% (primarily Twitter/X and LinkedIn)
- Technical Blogs & News: ~8% (HackerNews, AI blogs, tech publications)
- Other Referrals: ~7% (including documentation sites and partner websites)
The high proportion of direct traffic and GitHub referrals suggests Chroma has established a strong reputation within the developer community focused on AI applications.
Frequently Asked Questions about Chroma (FAQs)
General Questions about Chroma
Q: What exactly is Chroma?
A: Chroma is an open-source embedding database that makes it simple to build AI applications with embeddings. It allows you to store, query, and manage vector embeddings for semantic search and other AI applications.
Q: Is Chroma suitable for production use?
A: Yes, Chroma can be used in production environments. It offers persistent storage options and a client-server architecture for more robust deployments. For enterprise-scale needs, Chroma Cloud provides a managed option.
Q: How does Chroma compare to traditional databases?
A: Unlike traditional databases that focus on exact matches, Chroma specializes in similarity search using vector embeddings. This enables semantic understanding rather than keyword matching. Traditional databases excel at structured data, while Chroma excels at understanding meaning and context.
Q: Is Chroma only for text embeddings?
A: No, Chroma can store and query embeddings of any type, including those generated from text, images, audio, or any other data source. However, the most common use case currently is for text embeddings.
Feature Specific Questions
Q: What embedding models does Chroma support?
A: Chroma is model-agnostic and can work with embeddings from any source. It has built-in support for popular embedding models from providers like OpenAI, Cohere, and HuggingFace, but you can also use custom embeddings from any model.
Q: How many embeddings can Chroma handle?
A: The open-source version can handle millions of embeddings, depending on your hardware. For larger scales (tens or hundreds of millions), optimized deployment configurations or Chroma Cloud would be recommended.
Q: Does Chroma support metadata filtering?
A: Yes, Chroma allows you to store metadata alongside your embeddings and filter query results based on this metadata, enabling hybrid search capabilities.
Q: Can I update or delete embeddings after adding them?
A: Yes, Chroma supports updating and deleting embeddings through its API. You can update single embeddings or perform batch operations.
Pricing and Subscription FAQs
Q: Is Chroma really free to use?
A: Yes, the core Chroma database is open-source and free to use under the Apache 2.0 license. You can deploy it locally or self-host it without any licensing fees.
Q: What does Chroma Cloud cost?
A: Chroma Cloud pricing is customized based on usage requirements. You’ll need to contact the Chroma team for a specific quote based on your needs.
Q: Are there usage limits on the open-source version?
A: There are no artificial limits imposed on the open-source version. Any limitations would be based on your hardware capabilities and the efficiency of your implementation.
Support and Help FAQs
Q: Where can I get help with Chroma?
A: Several resources are available:
- GitHub repository issues for bug reports
- Discord community for user discussions
- Documentation and guides on the official website
- For Chroma Cloud customers, professional support channels
Q: Is there commercial support available for the open-source version?
A: The primary support for the open-source version comes from the community. For commercial support, Chroma Cloud offers professional support options.
Q: How do I report bugs or request features?
A: Bugs can be reported on the GitHub repository issue tracker. Feature requests can also be submitted there or discussed in the community Discord.
Conclusion: Is Chroma Worth It?
Summary of Chroma’s Strengths and Weaknesses
Strengths:
✅ Developer Experience: Chroma’s clean, intuitive API makes it accessible even to those new to vector databases.
✅ Open Source: The fully functional core being open source means no vendor lock-in and the ability to customize when needed.
✅ Integration: Excellent integration with popular ML frameworks and LLM tools, particularly LangChain.
✅ Flexibility: Works with various embedding models and deployment scenarios, from local development to cloud deployments.
✅ Community: Active development and a growing community provide resources and ongoing improvements.
Weaknesses:
❌ Enterprise Features: Some advanced features found in commercial alternatives are still in development.
❌ Scaling Complexity: While it can scale, doing so with very large datasets requires careful configuration.
❌ Documentation: Some advanced use cases could benefit from more comprehensive documentation.
❌ Maturity: As a relatively newer option, it doesn’t have the same track record as some alternatives.
Final Recommendation and Verdict
Chroma stands out as an excellent choice for developers looking to incorporate vector search and embedding management into their AI applications. Its combination of simplicity, flexibility, and powerful features makes it particularly well-suited for:
- Teams building LLM-powered applications
- Developers implementing semantic search
- Projects requiring quick implementation of RAG (Retrieval-Augmented Generation)
- Applications where developer experience and clean integration are priorities
For smaller to medium-scale applications, Chroma’s open-source version provides everything needed without cost. For larger enterprise deployments, Chroma Cloud offers a path to scalability with managed infrastructure.
Is Chroma worth it? Yes, particularly if you value:
- Developer productivity and ease of implementation
- Open-source flexibility
- Strong integration with the LLM ecosystem
- A balance of simplicity and power
While it may not be the absolute performance leader for massive-scale vector search (where specialized solutions like Pinecone or Milvus might edge ahead), Chroma offers the best balance of usability, flexibility, and performance for most LLM application development scenarios.
For most teams working on embedding-based applications, Chroma represents an excellent starting point that can grow with your needs, making it a recommended choice in the increasingly crowded vector database landscape.



